Которая ушла щи варить и пропала ))
она мои правки проверяла, всё работает, так что сейчас видимо кольцевым буфером и занимается )))
PS девочка слова, обещала - сделала!!!
Координаты головы и хвоста или голова и размер… не приходит в голову, что это одно и то же?
не совсем, если я храню позицию головы и размер, то например что бы отдать размер данных в буфере, я просто отдаю переменную.
А если я храню начало и конец данных, то размер хранящихся данных я должен вычислить, с учетом цикличности буфера.
Естественно, это не одно и то же. Хотя, безусловно, одно может быть легко сведено к другому.
И наоборот: чтобы поместить в буфер - надо знать, куда помещать, чтобы считать из буфера - надо знать, откуда считывать. Именно эти две операции обычно и производятся с кольцевым буфером. И для них не нужно никаких дополнительных вычислений.
А зачем вообще может понадобиться размер хранящихся в буфере данных, я даже не знаю.
IMHO выбор переменных дожен исходить из оптимальности наиболее часто производимых операций, а не из тех операций, которые вообще вряд ли кто когда будет использовать.
serial.available()
это самое простое зачем.
И вообще - не нравится - предложите свою реализацию ![]()
Сложновато
Что именно сложновато?
Пришёл байт от модема.
Ищу свободную позицию в буфере (изначально 0)
Записываю байт в 0 ячейку, и сдвигаю указатель на 1 (0+1 = 1)
Записываю следующий байт в 1 ячейку, 1+1 = 2
Записываю байт в 50 ячейку (буфер 50 байт).
Пришёл ещё один байт, 51, 51 больше 50 значит обнуляю позицию в буфере = 0
Записываю байт в 0 ячейку?
Или же пришёл 51 байт, значит я сдвигаю все 50 байт буфера влево, удаляя 0 ячейку, и записываю 51 байт в 50 ячейку?
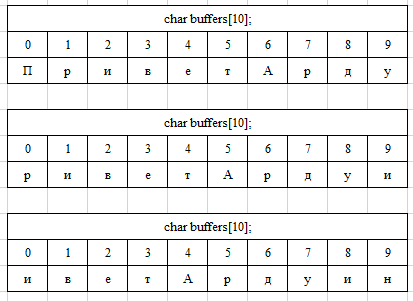
Ага, так.
Он потому “кольцевым” и называется, что по кругу “ходит”.
Вообще, если склероз мне не сильно изменяет, кольцевой буфер - это один из вариантов очереди (FIFO).
Может FILO?
Это стек
- Собственно, искать не нужно. Кольцевой буфер должен ее помнить в специально отведенной переменной.
Во-первых, если буфер 50 байт, то 50-й ячейки нет, последняя - 49. Кроме того, между 4 и 5 должно прийти еще 47 байтов. Буфер заполняется без пропусков - подряд.
А вот дальше - тонкости.
Если опираться на Википедию, то 50-й байт пишется именно в 0-ю ячейку. Ничего при этом не сдвигается (т.е. 8 не имеет места). Сдвиг элементов - дорогостоящая операция, а идея кольцевого буфера состоит в том, чтобы операции были максимально простыми и быстрыми.
Но большая часть практических реализаций работает не так, как описано в Википедии.
Пример 1: в случае ПК в виде кольцевого буфера реализован буфер клавиатуры. Если буфер переполняется, раздается звуковой сигнал, а в сам буфер ничего не заносится. Т.е. вновь пришедшие байты теряются (по Википедии должны теряться байты, пришедшие раньше всех).
Пример 2: Arduino - в виде кольцевого буфера реализуются входной и выходной буфера UART. По поводу входного буфера сказать не могу, а при попытке что-то поместить в выходной буфер при переполнении скетч приостанавливается до тех пор, пока UART не отправит очередной байт и, соответственно, не освободит ячейку в буфере. Т.е. потери не происходит, но UART начинает тормозить скетч.
First In First Out (FIFO) - “Первый пришел, первый ушел” - очередь.
First In Last Out (FILO) - “Первый пришел, последний ушел” - стэк.
Да, и так по кругу.
Т е все как и сейчас у вас реализовано, только убираете строки кода - очистка буфера. (Вру, первоначальная очистка буфера строго обязательна, заполняем нулем!)
Ну и вместо strstr пишем (используем код выше) для поиска подстроки в строке кольцевого буфера.
Спойлер
#include <SoftwareSerial.h>
SoftwareSerial SIM800(9, 2);
#define MAX_BUF 50
char buffers[MAX_BUF];
uint8_t pos;
void setup() {
Serial.begin(9600);
SIM800.begin(9600);
memset(buffers, 0, MAX_BUF);
}
void write_buffer(uint8_t temp) {
if (temp) {
if (pos >= MAX_BUF) pos = 0;
buffers[pos] = temp;
pos++;
}
}
void loop() {
if (Serial.available())SIM800.write(Serial.read());
if (SIM800.available()) write_buffer(SIM800.read());
static uint32_t tmr;
if (millis() - tmr >= 5000) {
tmr = millis();
for (byte i = 0; i < MAX_BUF ; i++) {
if (buffers[i] == '\r')buffers[i] = 'r';
if (buffers[i] == '\n')buffers[i] = 'n';
if (buffers[i] == ' ')buffers[i] = '*';
Serial.print(buffers[i]);
}
Serial.println("");
}
}

Осталось три ячейки памяти, ввожу ещё одну команду AT

Соответственно произошло смещение, всё верно.
На замену символов не обращайте внимания, для себя сделала
Как мне искать мои строки? К примеру жду +CCALR: 1
При каждом пришедшем байте проверять
if (strstr (buffers, “+CCALR: 1”) != NULL)
вот из относительно свежего
https://arduino.ru/forum/apparatnye-voprosy/vse-o-sim800l-i-vse-chto-s-nim-svyazano?page=5#comment-652617
все как обычно (похоже я код древний без изменений взял)
_Bool Sim800GPRS::findOKfromBuf(const unsigned char inByte) { // поиск OK\r\n в циклическом буфере
const char inStr[] = "OK\r\n"; // искомая строка
byte slen = 4; // длина искомой строки
if (inByte == inStr[slen - 1]) { // если последний символ совпадает - продолжаем искать всю строку
byte abpos = this->posRespBuf; // абсолютная позиция в буфере поиска-1 = последнему символу искомой строки
if (!abpos) abpos = _size_response_buf - 1; else --abpos; // ищем с предпоследнего символа
for ( byte i = 0; i < (slen - 1); ++i) { // цикл по оставшимся символам
if (inStr[slen - 1 - i] != this->mainBufResp[abpos]) return false; // если не сопадабт символы - выходим
if (!abpos) abpos = _size_response_buf - 1; else --abpos; // уменьшаем счетчики
}
} else {
return false;
} return true;
}
а вот ваш вариант, когда “жирный” МК, буфер большой и мы ищем тупо окончание строки \r\n
https://arduino.ru/forum/apparatnye-voprosy/raspberry-pi-pico?page=6#comment-666617
signed short findPosSubstringFromBuf(unsigned char * inStr) {
char * pStr = strstr((const char *) modemRXbuf, (const char *) inStr);
if (pStr) return (inStr - ((unsigned char*)pStr));
else return -1;
}
забудьте о готовых функциях, все ручками…
А проверять с конца искомой строки, потому что будет меньше действий выполняться?