Ну, что, мужики, давайте про задачу распарсивания списка страниц для печати.
На самом деле, он совсем не так проста, как тут пытались показать. Да, принципиально там всё просто, до тех пор, пока данные подготовлены без ошибок. Но как только мы допускаем возможно ошибок в данных, задача (если её реализовывать «в лоб») обрастает таким количеством «заплат», что «мама не горюй» и отлаживать её становится совсем не так просто.
Моё предложение – автомат с памятью. Это даст систематическое (а не «заплатное») решение. Известно, что главная (и единственная) стадия отладки автоматов – продумывание таблицы переходов. Готовая же таблица переходов переносится в код без ошибок, там негде ошибаться (и, кстати, существует много библиотек, позволяющих перенести таблицу переходов в код вообще без программирования, даже мы с вами тут такую делали).
Итак, прежде, чем строить автомат, давайте конкретизируем задачу.
Имеется входная строка (это может быть строка или поток байтов из последовательного порта или ещё что-нибудь).
Входной алафит:
- цифра – одно из { ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’ }
- дефис – знак «минус»
- конец строки – знак ‘\0’
- разделитель – пробел, запятая или любой другой символ, не упомянутый выше.
Из символов входного алфавита образуются лексемы:
- число – последовательность из одной или более идущих подряд цифр. Число может начинаться с нуля – это не означает ничего особенного. Число не может быть равно нулю. В этом случае, оно автоматически заменяется на единицу;
- диапазон – число или число с последующим дефисом в конце строки, или пара чисел, разделённых символом «дефис».
В последнем случае, первое число называется нижней границей диапазона, а второе – верхней. В случае диапазона состоящего из одного числа, обе его границы равны этому числу. Наконец, в случае диапазона, состоящего из числа и последующего дефиса в конце строки, нижняя граница диапазона равна этому числу, а верхняя специальному числу –lastPage(номеру последней страницы документа).
Входная строка состоит из нуля или более диапазонов. Диапазоны отделяются друг от друга одним или более разделителями. Внутри диапазона числа могут отделяться от дефиса нулём или более разделителей.
Развёрткой диапазона называется последовательность чисел от нижней до верхней границ диапазона включительно с шагом 1. В случае, если нижняя и верхняя границы равны между собой, развёртка состоит из одного числа, равного границам. В случае, если нижняя граница больше верхней, развёртка пустая.
Задача – преобразовать входную строку в выходную следующим образом: в выходной строке все диапазоны входной строки должны быть представлены своими развёртками.
В автомате присутствует память – две числовые переменные (lowNum и upNum), в которых будут храниться (и накапливаться) нижняя и верхняя границы диапазона по мере их ввода и разбора.
Также сразу определим вспомогательную функцию вывода диапазона (представленного нижней и верхней границами) в выходной поток. Это будет делаться по правилам, описанным выше:
void outputRange(const TPageNumber low, const TPageNumber high) {
for (TPageNumber i = (low ? low : 1); i <= (high ? high : 1); i++) {
Serial.print(i);
Serial.write(' ');
}
}
Т.е. развёртка, как и обсуждалось, может быть пустой, может состоять из одного числа, а может из последовательности чисел от нижней до верхней границы включительно с шагом 1. При этом, если числа – нули, они заменяются на 1, что тоже обсуждалось выше.
Также, наш автомат будет иметь состояние (state) и, по мере чтения строки, на каждом шаге будет доступен очередной входной символ (symbol)
Теперь пора переходить с состояниям. Всего состояний у нашего автомата будет пять:
WAITING_FOR_LOWER_BORDER – «ожидание нижней границы». Это изначальное состояние автомата. В нём он ожидает появления первой цифры нижней границы. Если в этом состоянии придёт входной символ:
Цифра – означает, что дождались. Цифру запомним как новое значение нижней границы (
lowNum) и перейдём в состояние «Ввод нижней границы»
Дефис – такого быть не может. Зафиксируем ошибку во входной строке и прекратим разбор
Конец строки – не дождались. Всё, что введено ранее уже преобразовано, так что просто завершаем разбор строки
Разделитель – игнорируем и переходим к следующему символу
WAITING_FOR_UPPER_BORDER – «ожидание верхней границы». Если мы в этом состоянии, значит, мы уже видели дефис и теперь ждём либо цифры (начала верхней границы), либо конца строки (тогда верхняя граница – lastPage). Таким образом, если в этом состоянии придёт входной символ:
Цифра – означает, что дождались. Цифру запомним как новое значение верхней границы (
upNum) и перейдём в состояние «Ввод верхней границы»
Дефис – такого быть не может – это уже второй дефис подряд. Зафиксируем ошибку во входной строке и прекратим разбор
Конец строки – выводим в выходную строку диапазон (lowNum–lastPage) и завершаем разбор строки
Разделитель – игнорируем и переходим к следующему символу
ENTERING_LOWER_BORDER – «ввод нижней границы». Это означает, что первую цифру мы уже ввели, и она запомнена в переменной lowNum. Здесь мы можем ожидать последующих цифр или завершения числа тем или иным способом. Если в этом состоянии придёт входной символ:
Цифра – нужно старое значение
lowNumумножить на 10, сложить с поступившей цифрой и запомнить как новое значениеlowNum. Так и будем число накапливать по мере ввода.
Дефис – нижняя граница закончилась. Дефис указывает, что нам надо ожидать верхней. Так и поступаем – переходим в состояние «ожидание верхней границы».
Конец строки – диапазон закончился. Верхней границы не будет. Выводим на выход диапазон (lowNum,lowNum) и заканчиваем обработку.
Разделитель – нижняя граница закончилась, возможно, потом последует дефис, поэтому переходим в состояние «ожидание дефиса».
ENTERING_UPPER_BORDER – «ввод верхней границы». Это означает, что первую цифру мы уже ввели, и она запомнена в переменной upNum. Здесь мы можем ожидать последующих цифр или завершения числа тем или иным способом. Если в этом состоянии придёт входной символ:
Цифра – нужно старое значение
upNumумножить на 10, сложить с поступившей цифрой и запомнить как новое значениеupNum. Так и будем число накапливать по мере ввода.
Дефис – такого быть не может. Верхняя граница справа от дефиса, после неё дефиса не бывает. Зафиксируем ошибку во входной строке и прекратим разбор
Конец строки – всё нормально, диапазон закончился, выводим диапазон (lowNum,upNum) и завершаем разбор строки
Разделитель – опять же, этот диапазон закончился. Выводим значение (lowNum,upNum) и начинаем ждать следующего диапазона, т.е. переходим в состояние «ожидание нижней границы»
WAITING_FOR_HYPHEN – «ожидание дефиса». В этом состоянии мы находимся после того, как нижняя граница закончилась разделителем. Мы можем дождаться либо дефиса (тогда будем ожидать верхней границы), либо цифры, которая будет первой цифрой нижней границы нового диапазона, либо конца строки. Если в этом состоянии придёт входной символ:
Цифра – означает, старый диапазон закончился (верхняя граница равна нижней) и мы дождались первой цифры нижней границы нового диапазона. Поэтому, выводим диапазон (
lowNum,lowNum), полученную цифру запомним как новое значение нижней границы и перейдём в состояние «Ввод нижней границы»
Дефис – дождались. Переходим в состояние «ожидание верхней границы»
Конец строки – не дождались. Стало быть, у текущего диапазона верхней границы нет. Выводим диапазон (lowNum,lowNum) и завершаем разбор строки
Разделитель – игнорируем и переходим к следующему символу
Ну, вот как-то так. Логика работы описана, вроде, строго, однозначно и точно.
Теперь изобразим всё сказанное в виде таблицы переходов между состояниями. В левом столбце перечислены все состояния автомата. Каждый последующий столбец соответствует классу входного символа. Этот «класс» указан в первой строке. Как видите, таблица покрывает все возможные состояния и все возможные входные симвлолы.
Читать таблицу следует так: если автомат находится в состоянии (из первого столбца) и пришёл символ (из первой строки) то, нужно сделать то, что написано на пересечении этих столбца и строки. Например, «если автомат находится в состоянии ENTERING_LOWER_BORDER и пришёл символ S_HYPHEN (дефис), то нужно (смотрим на пересечение) сменить состояние на WAITING_FOR_UPPER_BORDER.
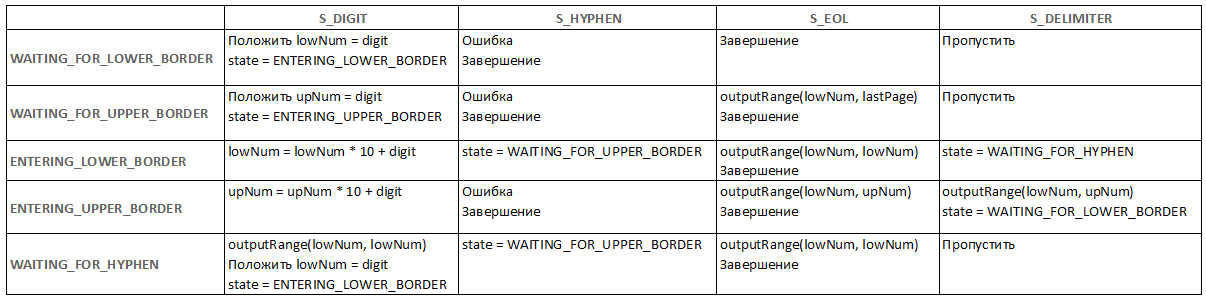
Теперь посмотрите и убедитесь, что таблица полностью соответствует приведённым выше словесным рассуждениям. Это очень важно. Это и есть отладка автомата. Таблица должна правильно отражать логику работы.
Полюбовались на таблицу? Сравнили?
Ну, теперь к программной реализации. Если отбросить «оформительство», то вся программа содержится в функции parseAutomata. Положите текст этой функции возле таблицы (лучше распечатать) и убедитесь, что в функции нет ничего – это просто один к одному переписанная на ЯП таблица. Т.е. вообще ничего – просто записал таблицу через if-else (можно было через switch) и всё.
Собственно код
// Тип для номеров страниц
typedef unsigned int TPageNumber;
//
// Классы возможных символов
// см. функцию analyzeSymbol ниже
//
enum TypeOfSymbol {
S_DIGIT, // цифра - одно из { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9' }
S_HYPHEN, // дефис - знак '-'
S_EOL, // конец строки - знак '\0' (можно использовать любой символ)
S_DELIMITER // любой другой знак, не упомянутый выше
};
//
// Состояния автомата
//
enum AutomataState {
WAITING_FOR_LOWER_BORDER, // ожидание нижней границы диапазона
WAITING_FOR_UPPER_BORDER, // ожидание верхней границы диапазона
WAITING_FOR_HYPHEN, // ожидание символа дефис
ENTERING_LOWER_BORDER, // в процессе ввода числа - нижней границы диапазона
ENTERING_UPPER_BORDER // в процессе ввода числа - верхней границы диапазона
};
//
// Возможные результаты разбора
//
enum AutomataResult {
PA_OK = 0,
PA_ERROR
};
//
// Возвращает класс символа, переданного параметром
//
TypeOfSymbol analyzeSymbol(const char symbol) {
if (isdigit(symbol)) return S_DIGIT;
if (symbol == '-') return S_HYPHEN;
if (symbol == '\0') return S_EOL;
return S_DELIMITER;
}
//
// Синтаксический сахар
//
inline TPageNumber symbol2digit(const char symbol) {
return symbol - '0';
}
//
// Вывод диапазона в поток
// Если одна (или обе) из границ диапазона - ноль,
// вместо нуля используется единица
//
void outputRange(const TPageNumber low, const TPageNumber high) {
for (TPageNumber i = (low ? low : 1); i <= (high ? high : 1); i++) {
Serial.print(i);
Serial.write(' ');
}
}
//
// Собственно автомат разбора
//
AutomataResult parseAutomata(const char * str, const TPageNumber lastPage) {
AutomataResult result = PA_OK;
AutomataState state = WAITING_FOR_LOWER_BORDER;
TPageNumber lowNum = 0, upNum = 0;
//
// По строке str проходим один раз, никаких возвратов
// Что и в каком состоянии делать, дословно прописано по таблице
// Ничего такого, чего бы там не было.
//
for (bool running = true; running; str++) {
const char symbol = * str;
const TypeOfSymbol sType = analyzeSymbol(symbol);
if (state == WAITING_FOR_LOWER_BORDER) {
if (sType == S_DIGIT) {
lowNum = symbol2digit(symbol);
state = ENTERING_LOWER_BORDER;
} else if (sType == S_HYPHEN) {
result = PA_ERROR;
running = false;
} else if (sType == S_EOL) {
running = false;
} else { // (sType == S_DELIMITER)
}
}
//
else if (state == WAITING_FOR_UPPER_BORDER) {
if (sType == S_DIGIT) {
upNum = symbol2digit(symbol);
state = ENTERING_UPPER_BORDER;
} else if (sType == S_HYPHEN) {
result = PA_ERROR;
running = false;
} else if (sType == S_EOL) {
outputRange(lowNum, lastPage);
running = false;
} else { // (sType == S_DELIMITER)
}
}
//
else if (state == ENTERING_LOWER_BORDER) {
if (sType == S_DIGIT) {
lowNum = lowNum * 10 + symbol2digit(symbol);
} else if (sType == S_HYPHEN) {
state = WAITING_FOR_UPPER_BORDER;
} else if (sType == S_EOL) {
outputRange(lowNum, lowNum);
running = false;
} else { // (sType == S_DELIMITER)
state = WAITING_FOR_HYPHEN;
}
}
//
else if (state == ENTERING_UPPER_BORDER) {
if (sType == S_DIGIT) {
upNum = upNum * 10 + symbol2digit(symbol);
} else if (sType == S_HYPHEN) {
result = PA_ERROR;
running = false;
} else if (sType == S_EOL) {
outputRange(lowNum, upNum);
running = false;
} else { // (sType == S_DELIMITER)
outputRange(lowNum, upNum);
state = WAITING_FOR_LOWER_BORDER;
}
}
//
else { // (state == WAITING_FOR_HYPHEN)
if (sType == S_DIGIT) {
outputRange(lowNum, lowNum);
lowNum = symbol2digit(symbol);
state = ENTERING_LOWER_BORDER;
} else if (sType == S_HYPHEN) {
state = WAITING_FOR_UPPER_BORDER;
} else if (sType == S_EOL) {
outputRange(lowNum, lowNum);
running = false;
} else { // (sType == S_DELIMITER)
}
}
}
Serial.println();
return result;
}
//
// Запуск одного теста с печатью исходной строки и результата
//
void doOneTest(const char * s) {
Serial.print('"');
Serial.print(s);
Serial.println('"');
AutomataResult res = parseAutomata(s, 20);
Serial.println(res == PA_OK ? "Нормально" : "Хреново");
Serial.println();
}
//
void setup(void) {
Serial.begin(9600);
Serial.println("Поехали!!!");
doOneTest("1");
doOneTest("1 2 3-6");
doOneTest("4-7, 9, 16-");
doOneTest("3 и 5-7 и ещё 19");
doOneTest("5-7-9");
doOneTest("2 5-8 11 10-9 15-15 18-");
doOneTest("0 - 7");
}
void loop(void) {}
Вот поэтому я и говорю, что отладка автомата – проверка и выверка таблицы. Когда таблица уже готова, там ошибаться просто негде.