Нарисовал программулину, как быть увереным что в программе все дескрипторы выделения памяти корректно освобождаются и нет утечек?
Можно ли следить за объемом выделяемой памяти в htop и если цифры не увеличиваются - быть уверенным что все хорошо?
Делает то она не особо сложные вещи, берет с сервера через zabbix api проблемы и отображает их на экране.
Вопрос насколько корректно я использовал malloc/realloc/free чтоб программа могла стабильно работать максимально возможное время не зависнув и не завесив всю ОС.
С объектами какого размера ты работаешь, если тебе на Оранж Пай приходится реально пользоваться динамической памятью?
Но если беспокоишься, то просто выведи в лог занятую память и проследи сутки.
Но лучший способ не переживать за кучу - ей не пользоваться Есть же стек.
А так есть приемы “для джунов”, чтобы проверять себя. Например при вызове malloc сперва проверять, что указатель не определен. И так далее. самые простые приемы себя защитить от своих ошибок. Есть целые библиотеки написанные для этого. Но в маленьком коде это скорее всего не нужно
Есть несколько замечаний.
Писать на процедурном С, не на С++ - это просто тренировка навыков или позиция?
Ну это я к тому, что для применения языка такого низкого уровня нужен повод. Причина простая - на столь низком уровне нет средств нормального управления памятью. Для такой мелочи - не особо страшно, но привычки так работать с памятью при программировании на С быть не должно. Языки высокого уровня, и даже просто С++ с нормальным STL имеет средства для строк и списков и вопрос мелкого фрагментирования памяти уже не касается программиста. А на С нужно про это думать самому. Для очень мелких объектов “бест практис” это просить память у системы большими кусками, если не хватило. И управлять самостоятельно мелочью.
Но я бы порекомендовал использовать нормальные реализации списков и строк в С++
Есть OrangePI, работающий иногда в качестве шлюза между двумя сетями, есть ili9341, есть свободное время - почему бы не сделать колхоз, который повесить перед глазами на рабочем месте
Snmp ну вообще не мой случай, в zabbix же не только сетевые устройства, не буду же я для например Windows служб отдельный метод проверки делать, для Linux ещё какой то, проще с готового zabbix сервера взять уже готовую информацию о проблемах.
от ИИ советы нужны ?))
в массиве с плавающей памятью легко запутаться))) и лучше зарезервировать массив заранее, но у вас наверное дело в нехватке памяти…
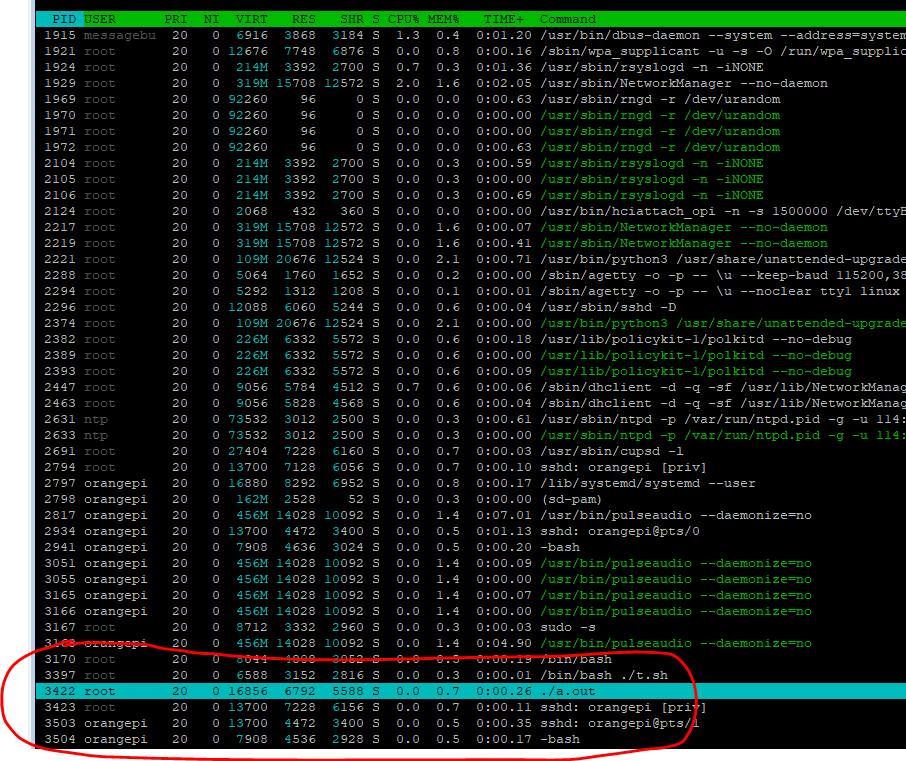
Итак через сутки работы память занимаемая увеличилась почта в два раза.
Явно где то не освобождается, вопрос в моей программе косяк или в используемых библиотеках curl и/или json.
==4077==
==4077== HEAP SUMMARY:
==4077== in use at exit: 9,217 bytes in 147 blocks
==4077== total heap usage: 28,463 allocs, 28,316 frees, 3,122,308 bytes allocated
==4077==
Для zabbix надо настроить snmptrap, чтобы он слал событие, а ваша программа в виде snmptrapd (стандартная для любой системы) будет реагировать. Не надо дергать zabbix за одно место ( api) , пусть он сам шлет. При этом вы получите стадартный обработчик, который без zabbix может работать.
Почуствуйте разницу. Система прибита гвоздями к zabbix или имеет стандартный протокол, который предназначен для этих целей. Тем более, что исходники snmptrapd есть и отлажены годами.
Вам нужно написать враппер на malloc/free: на каждый malloc увеличивать счетчик, на каждый free() - уменьшать. Дайте программе поработать подольше, а сами следите за своим счетчиком. Ежели счетчик постоянно растет - у вас утечка. Если он ходит то вверх то вниз, то утечек нет.
Враппер может быть как целиком самописный (т.е. делает свои my_malloc(), my_calloc(), my_realloc() и my_free() и заменяете все вызовы на эти) . Тогда в учет не попадут аллокации сделанные glibc + надо везде заменять вызовы.
Если нужно учесть “всё, вообще всё” то вам нужно раскурить опции линкера
-Wl,--wrap=malloc -Wl,--wrap=free
И почитать link-time function call wrapping: можно заставить линкер подменить вызов malloc на my_malloc, причем глобально: замена произойдет и в свежескомпиленном коде и в бинарниках (в glibc, например)