struct SExample {
// конструктор, рассчитываем на этапе компиляции
constexpr SExample(const char* const str)
: _str(str) {}
// длина строки в UTF-8
size_t strlenUtf8(void) const {
size_t res = 0;
const char* ptr = _str;
for (; *ptr; ptr++)
if ((*ptr & 0xc0) != 0x80) res++;
return res;
}
protected:
const char* const _str;
};
SExample ex = SExample("Пример");
void setup() {
// put your setup code here, to run once:
Serial.begin(115200);
Serial.print(ex.strlenUtf8());
}
void loop() {
// put your main code here, to run repeatedly:
}
Функция strlenUtf8 возвращает количество символов _str в формате UTF-8.
Строка “Пример” по адресу str известна при компиляции.
Можно как-то рассчитать на этапе компиляции и длину этой строки?
Что-то типа:
struct SExample {
// конструктор, рассчитываем на этапе компиляции
constexpr SExample(const char* const str)
: _str(str), _len_utf8(strlenUtf8(str)) {}
// длина строки в UTF-8
size_t strlenUtf8(const char *ptr /* const s*/) const {
size_t res = 0;
// const char* ptr = s;
for (; *ptr; ptr++)
if ((*ptr & 0xc0) != 0x80) res++;
return res;
}
size_t length(void) const { return _len_utf8; }
protected:
const char* const _str;
const size_t _len_utf8;
};
SExample ex = SExample("Пример");
void setup() {
// put your setup code here, to run once:
Serial.begin(115200);
Serial.print(ex.length());
}
void loop() {
// put your main code here, to run repeatedly:
}
У Вас IDE из коробки? Для AVR? Или что? А то с разными версиями языка там разная трудоёмкость. На современных, так почти вообще ничего менять в Ваших кодах не надо, а если “из коробки” (С++ 11) придётся функцию расчёта длины немного изменить.
Вот смотрите. Я оставил практически полностью Ваш код, но изменил функцию подсчёта длины (про неё позже).
Также я добавил макрос WITH_CALC (первая строка). Если указать там true, то компилируется Ваш вариант, а если false – то такая же структура но безо всяких вычислений с голимыми константами. Это было сделано для проверки. Теперь Вы можете скомпилировать c true и с false и сравнить размер кода и данных. Как видите, размеры идентичны. Это доказывает, что все вычисления были сделаны компилятором, а в код попали только готовые константы.
Теперь про функцию подсчёта длины.
она не использует никакие поля структуры (и не может, т.к. Вы её вызываете до создания экземпляра). Значит, она просто просится быть static.
Вы вызываете её в constexpr-конструкторе, значит она обязана быть constexpr
В С++11 (а “искаропки” указан именно он) тело constexpr-функции обязано состоять из единственного оператора return, поэтому я переписал её соответствующим образом (кстати, я не проверял Ваш вариант на корректность, просто переписал один в один)
Вы четко и последовательно разъяснили все, чего я не понимал в constexpr выражениях.
И очень красиво показали рекурсивную реализацию подсчета количества символов. До этого сам бы я никогда не додумался.
Меня в своё время сильно позабавила мысль, что парсер языка C++ - это тьюринг-полная машина (в частности неразрешима проблема остановки, то есть может быть программа распарсена еще до стадии компиляции или нет).
Восхитительный всё-таки язык насколько замшелый настолько и просвечивающий жемчугом из под замшелости.
Правильные пацаны давно перешли на Rust.
Все жду SDK Arduino под Раст. Смешно будет выглядеть. Хотя его защита не порождает особенно избыточного кода. Но все равно смешно будет!
Не, под Распберри или СТМ или ЕСП32 - норм, но под АВР это будет бомба!!!
Что-то Вы перепутали. С++ имеет регулярную грамматику (как и все сколько-нибудь известные языки), так что нету там в парсере никакой проблемы останова.
Нерегулярная грамматика, например, у e-mail адресов. Потому, в природе не существует регулярного выражения, которые бы всегда, во всех случаях, правильно распознавало e-mail адрес. Есть масса приближений, но чтобы всегда, полностью по RFC 5322 – фигушки. Есть некие допущения (упрощённый формат) которые позволяют таки уйти от нерегулярности и построить нормальный верификатор.
Было уже несколько предложений в комитет стандартов по упрощению и приведению к регулярности. Но пока это не реализовано и полностью проверить адрес регулярным выражением невозможно. Не потому, что никто не придумал как, а потому, что существует математическое доказательство того, что нерегулярные грамматики не описываются регулярными выражениями.
На эту тему:
научная работа (из Оксфордского университета) где всё подробненько и где вводятся минимальные ограничения, позволяющие уйти от нерегулярности и таки проверить почти все возможные адреса;
а вот статья на том же хабре, где человек, который, похоже, ничего не слышал о нерегулярных грамматиках, гордо заявляет, что он построил такое регулярное выражение (не проверял, но вполне верю, что он построил достойное регулярное выражение, которое проверит все разумные адреса. Беда только в том, что они могут быть "неразумными")
Ну, и на сладкое: вот Вам одно из наиболее продвинутых регулярных выражений, которое проверяет корректность e-mail адреса почти полностью по RFC5322
Дело не в грамматиках как таковых, а в шаблонном коде - шаблон может войти в рекурсию - причём “управляемую параметрами” рекурсию - ровно как в ФП, поэтому распахивается весь спектр “циклов через функции” и тому подобное - метапрограммирование тьюринг-полно.
В результате можно завесить компилятор на этапе еще до фазы генерации кода, во время составления AST или где то рядом - на попытке выяснить что за класс у нас в руках.
Ну, знаете, такие вещи частенько пишут “умники” с почти обязательно припиской “Гы”. На самом деле, это, конечно же, не так.
Это было БЫ так, если БЫ разработчики языка об этом БЫ не подумали. Ну, а поскольку они подумали, такие заявления – просто спекуляция для тех, кто недостаточно знает язык и главное слово здесь – “БЫ”.
Глубина рекурсии шаблонов в языке ограничена (см. ISO/IEC 14882:2020, § 13.9.2 (17)). Заметьте, именно в языке, а не в реализации. Т.е. стандарт языка требует от реализаций ограничивать глубину рекурсии некоторым числом (рекомендует 1024, но тут у реализации есть некая свобода, например, в gcc ограничение задаётся параметром-ftemplate-depth, по умолчанию – 900).
Так что правильно (в соответствии со стандартом языка) написанный компилятор не зависнет, не беспокойтесь.
Можно, конечно, сказать, что “это искусственное ограничение, а вот, если бы не оно …”, но это уже как у Высоцкого: “если б ту черту, да к чёрту отменить, …” то бабушка была бы дедушкой.
А вот, за то, что напомнили про шаблоны, спасибо. Я выше писал
и собирался привести ещё пару способов (по меньшей, мере назвать), но забыл. Сейчас как раз есть полчасика, подготовлю для мужиков красивый примерчик на шаблонах.
А потом, после того как показал реализацию на constexpr функции как-то забыл раскрыть эту фразу. Извиняюсь, сейчас исправлю.
Итак, кроме constexpr функций для вычислений во время компиляции также годятся шаблоны и препроцессор. И там и там можно сделать то же самое, что мы делали выше, т.е. посчитать длину utf-8 строки во время компиляции.
Ну, с препроцессором сделать-то можно, но гороху откушать надо немало, а я только что пообедал – не хочется (но сделать точно можно!). (справедливости ради, на препроцессоре можно и просто сделать, если воспользоваться замечательной библиотекой Boost C++, но я далёк от мысли здесь её рекламировать).
А вот с шаблонами могу показать, смотрите. Я постарался прокомментировать, так-то там всего шесть строк, если комментариев не считать. Сделано также, как и раньше, если WITH_CALC true то идёт расчёт, а если false, вставляются голимые константы. Как видите размер кода и данных ни на байт не отличается.
#define WITH_CALC true
//
// Строковую константу для передачи в качестве параметра шаблона,
// надо объявлять ИМЕННО МАССИВОМ, А НЕ УКАЗАТЕЛЕМ.
// Запись
// constexpr char * str = "Ну, сказала Сова ..."; // 20 символов
// НЕ ПРОКАТИТ
//
constexpr char str [] = "Ну, сказала Сова ..."; // 20 символов
//
#ifdef WITH_CALC
//
// Общая идея шаблонных вычислений: строится базовый шаблон, который вычисляет
// необходимую величину "в большинстве случаев", и к нему добавляются специализированные шаблоны
// с тем же именем, которые вычисляют частные случаи (при каких-то конкретных значения параметров)
//
// В данном примере базовый шаблон просто считает, что длина строки равна 1 + длина строки, оставшейся
// после отбрасывания первого (текущего) символа. К нему добавляются два специализированных шаблона.
// Первый - на случай, когда текущий символ является специальным префиксом UTF8, тогда он не
// учитывается, а длина строки равна длине оставшейся после отбрасывания текущего символа строки.
// Второй - на случай, когда текущий символ равен '\0' - это позволяет прервать рекурсию и завершить
// вычисления.
//
// Базовый шаблон
//
// Параметры (для обращения нужен только первый, остальные - внутренняя кухня):
// p - строка для подсчёта длина. Должна быть constexpr и массив, а не указатель (см. выше)
// ds - номер текущего символа в массиве. Изначально - 0
// с - текущий символ массива
// isUTFPrefix - true, если текущий символ является префиксом символа UTF8 и false в противном случае
// Результат:
// создаёт структуру LC с единственным статическим полем length
// Алгоритм:
// Присваивает полю length 1 + длину оставшейся строки (начиная с p[ds+1])
//
template<const char * p, size_t ds = 0, char c = p[ds], bool isUTFPrefix = (p[ds] & 0xc0) == 0x80>
struct LC { static const size_t length = 1 + LC<p,ds+1,p[ds+1]>::length; };
//
// Первый специализированный шаблон (для случая, когда isUTFPrefix равен true)
// Отличается от базового только тем, что не прибавляет 1 в результат
//
template<const char * p, size_t ds, char c>
struct LC<p, ds, c, true> { static const size_t length = LC<p,ds+1,p[ds+1]>::length; };
//
// Второй специализированный шаблон (для случая, когда текущий символ равен '\0')
// Просто говорит, что длина строки 0 и больше не вызывает шаблонов (заканчивает рекурсию)
//
template<const char * p, size_t ds>
struct LC<p, ds, '\0', false> { static const size_t length = 0; };
//
// Здесь мы просто вызываем наш шаблон и константа theLength получает значение,
// равное вычисленной длине строки
//
constexpr size_t theLength = LC<str>::length;
#else // WITH_CALC
// А тут мы ничего не вычисляем, просто забиваем готовую константу
constexpr size_t theLength = 20;
//
#endif // WITH_CALC
//
void setup(void) {
Serial.begin(9600);
Serial.print("Длина (\"");
Serial.print(str);
Serial.print("\": ");
Serial.println(theLength);
}
void loop(void) {}
Я уж вторую неделю пытаюсь писать статью для своего раздела про шаблоны (третий раз с нуля начинаю). Вот появился шанс поспойлерить, может это подстегнёт таки закончить
Там же можно всё что угодно посчитать на этапе компиляции (лишь бы все исходные данные были известны) – практически любой сложности расчёты исключительно на шаблонах. Например, там в статье я рассчитываю параметры инициализации таймера (делитель частоты и количество тиков), чтобы получить нужный временной интервал. На constexpr мы это уже делали раньше, вот теперь будет то же самое на шаблонах.
Воу воу, я правда так выразился, my bad, это совершенно неверно конечно же.
Не знаю даже уже теперь о чём думал, что вставил такую комбинацию слов. Как минимум должен был заключить слово “завесить” в кавычки, чтобы обозначить, что речь не про буквальность.
Само понятие “тюринг-полноты” применительно к ЭВМ это всегда куча подразумевающихся оговорок.
Даже реальная программа “повисшая” на рекурсии на практике не выполняется бесконечно, а вываливается со “stack overflow” и да, у компилятора эдакий аналог стека для инстанциаций действительно есть.
Наш уважаемый участник Евгений меня не видит ;). Но остальным будет полезно знать, что по формальной классификации (по Хомскому) никакой ЯП, конечно не является регулярным языком. И грамматика - конечно не регулярная. Даже язык обычной школьной арифметики со скобками - УЖЕ не регулярный. Это язык, разбираемый на автомате со стековой памятью, но не на Конечном Автомате. Так как конечным количеством состояний нельзя предусмотреть ЛЮБУЮ вложенность скобок.
Новый участник примерно это и хотел сказать, пусть и несколько косноязычно.
отдельнго добавлю, для любопытных: класс грамматик современных ЯП даже к Конкстно Свободным нельзя отнести полностью точно, так как есть зависимоти от контекста. Не всегда разрешимые вводом дополнительных символов.
Яркий пример - приоритеты операций. Это контекстная зависимость, но разрешимая. Путем ввода на просто операндов, а множителей и слагаемых отдельно. Но не всегда так можно сделать. Или иногда можно лишь невероятным, нечитаемым усложнением грамматики. Так что современные Синтаксические Анализаторы (почти все создатели компиляторов используют Bison - наследник YACC) это LALR(1) анализатор с элементами анализа контекста. Переведу акроним - синтаксический анализатор “снизу вверх” - то есть от простых элементов языка (термов) к сложным. С просмотров потока слева направо и принятием решения на основе (1) одного предварительно просматриваемого символа (лексемы).
А регулярные языки это и правда то, что можно определить через Регулярные Выражения. Это то, что определяет Лексемы наших ЯП. Лексема это, к примеру - Имя переменной, Литерал, Оператор, Знак операции и так далее.
Я слабо шарю в теории грамматик, жизнь сталкивала только с тем, что по BNF (если память не изменяет) какие то моменты прояснял для языка для себя. Вот последний раз совсем недавно был - язык B разбирал и делал статейку по нему, как он повлиял на Си (а повлиял фундаментально, конечно) и неправильно изначально понял один момент изложенный текстом, но всё прояснилось из грамматики.
Но в чём суть той мысли что я хотел передать - что почти все распространённые в массах языки в своём парсере не имеют проблемы остановки. Вот просто не имеют и всё - если взять конечную программу и запустить на ней компилятор, то есть гарантия, что имея достаточно памяти мы её успешно распарсим в AST над которым уже может начать трудится кодогенераторная часть компилятора.
C++ же за счёт метапрограммирования подкидывает проблему остановки - можно несколькими строками кода задать парсеру неразрешимую задачку и вот именно поэтому в стандарт и надо закладывать пункт про ограничение рекурсии.
Плюс еще одну забавность подброшу, вот сейчас прям обнаружил - про constexpr функции, ведь понятно, что с ними нужна та же осторожность и действительно вот такая программа не скомпилируется с сообщением об ошибке превышения уровней вложенности (в случае ideone: “error: ‘constexpr’ evaluation depth exceeds maximum of 512 (use -fconstexpr-depth= to increase the maximum)”).
#include <iostream>
using namespace std;
constexpr int func(const int i)
{
return func( i );
}
int main() {
constexpr int x = func(10);
std::cout << x << "\n";
return 0;
}
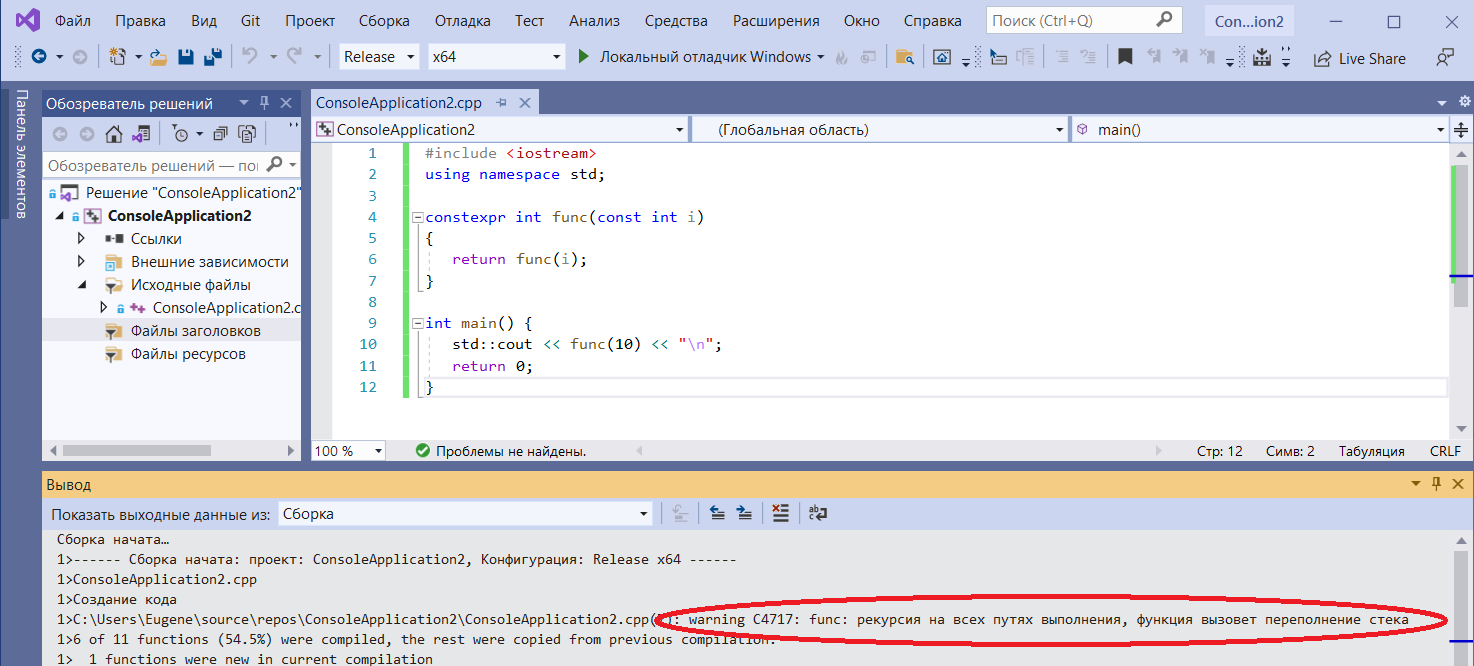
Но немного модифицируем программу и:
#include <iostream>
using namespace std;
constexpr int func(const int i)
{
return func( i );
}
int main() {
std::cout << func(10) << "\n";
return 0;
}
и она успешно скомпилируется! Только зависнет на этапе выполнения.
Забавно, т.е. компилятору в таких случаях, когда на constexpr нельзя настаивать разрешено (или приказано) увести вычисление в рантайм столкнувшись с лимитом.
Кто Вам сказал? Плюньте в рожу. Я всё вижу, т.к. не пользуюсь (и никогда не пользовался) средствами “игнорировать”. Поэтому, давайте придерживаться установленного правила. Я Вас не трогаю и ожидаю того же от Вас.
Точно? Вы сами пробовали? Или Вы больше по части поговорить, а не попробовать?
У меня вот, например, она выдала вполне понятное и читабельное предупреждение, а потому не считаю возможным говорить, что она “успешно скомпилировалась”